第二十一章:格式化输出
在本章中,我们将继续研究与文本相关的工具,重点关注用于格式化文本输出的程序,而不是更改文本本身。这些工具通常用于为最终打印准备文本,我们将在下一章介绍这一主题。本章将介绍以下程序:
nl—— 行号,number linesfold—— 将每行包裹到指定长度fmt—— 一个简单的文本格式化程序pr—— 准备打印文本printf—— 格式化和打印数据groff—— 文档格式化系统
第二十一章:格式化输出简单格式化工具nl —— 行号fold —— 将每行包裹到指定长度fmt —— 一个简单的文本格式化工具pr —— 为打印格式化文本printf —— 格式化和打印数据文档格式系统groff总结
简单格式化工具
我们先来看看一些简单的格式化工具。这些大多是单用途(single-purpose)程序,它们的功能有点简单,但它们可以用于小任务,也可以作为管道和脚本的一部分。
nl —— 行号
nl程序是一个相当神秘的工具,用于执行简单的任务。它对行进行编号。在最简单的用法中,它类似于 cat -n 。
xxxxxxxxxx[me@linuxbox ~]$ nl distros.txt | head 1 SUSE 10.2 12/07/2006 2 Fedora 10 11/25/2008 3 SUSE 11.0 06/19/2008 4 Ubuntu 8.04 04/24/2008 5 Fedora 8 11/08/2007 6 SUSE 10.3 10/04/2007 7 Ubuntu 6.10 10/26/2006 8 Fedora 7 05/31/2007 9 Ubuntu 7.10 10/18/2007 10 Ubuntu 7.04 04/19/2007与 cat 一样, nl 可以接受多个文件作为命令行参数或标准输入。然而, nl 有许多选项,并支持原始形式的标记,以允许更复杂的编号。
nl 在编号时支持一个称为“逻辑页面(logical pages)”的概念。这允许 nl 在编码时重置(重新开始)数字序列。使用选项,可以将起始编号设置为特定值,并在有限范围内设置其格式。逻辑页面进一步细分为页眉、正文和页脚。在每个部分中,行号可以重置和/或分配不同的样式。如果 nl 有多个文件,它会将它们视为单个文本流。文本流中的部分由添加到文本中的一些看起来相当奇怪的标记表示,如下表所述:
| 标记(markup) | 含义 |
|---|---|
| \:\:\: | 逻辑页眉开始 |
| \:\: | 逻辑页面正文开始 |
| \: | 逻辑页脚开始 |
上表中列出的每个标记元素都必须单独出现在自己的行中。处理标记元素后, nl 会将其从文本流中删除。
下表列出 nl 常见选项:
| 选项 | 含义 |
|---|---|
| -b style | 将主体编号设置为样式,其中样式为以下之一:a =对所有行进行编号t =仅对非空白行进行编号。这是默认设置。n =无pregexp =匹配基本正则表达式正则表达式的行数。 |
| -f style | 将页脚编号设置为 style 。默认值为 n (无)。 |
| -h style | 将标题编号设置为 style 。默认值为 n (无)。 |
| -i style | 将页码增量设置为 number 。默认值为 1 。 |
| -n format | 将编号格式设置为格式,其中格式为以下之一:ln =左对齐,不带前导零。rn =右对齐,没有前导零。这是默认设置。rz =右对齐,有前导零。 |
| -p | 不要在每个逻辑页的开头重置页码。 |
| -s string | 在每个行号的末尾添加 string 以创建分隔符。默认值是单个制表符。 |
| -v number | 将每个逻辑页的第一行编号设置为 number 。默认值为 1 。 |
| -w width | 将行号字段的宽度设置为 width 。默认值为 6 。 |
诚然,我们可能不会经常给行编号,但我们可以使用 nl 来研究如何组合多个工具来执行更复杂的任务。我们将在前一章的工作基础上,编写一份Linux发行版报告。由于我们将使用 nl ,因此包含其页眉/正文/页脚(header/body/footer)标记将非常有用。为此,我们将把它添加到上一章的sed脚本中。使用我们的文本编辑器,我们将按如下方式更改脚本并将其另存为 distros-nl.sed :
xxxxxxxxxx# sed script to produce Linux distributions report 1 i\\\:\\:\\:\ \ Linux Distributions Report\ \ Name Ver.Released\ ---- ------------\\\:\\: s/\([0-9]\{2\}\)\/\([0-9]\{2\}\)\/\([0-9]\{4\}\)$/\3-\1-\2/ $ a\ \\:\ \ End Of Report脚本现在插入 nl 逻辑页面标记,并在报告末尾添加页脚。请注意,我们必须在标记中加倍反斜杠,因为它们通常被 sed解释为转义符。
接下来,我们将通过组合 sort 、 sed 和 nl 来生成增强的报告。
xxxxxxxxxx[me@linuxbox ~]$ sort -k 1,1 -k 2n distros.txt | sed -f distros-nl.sed | nl Linux Distributions Report Name Ver. Released ---- ---- -------- 1 Fedora 5 2006-03-20 2 Fedora 6 2006-10-24 3 Fedora 7 2007-05-31 4 Fedora 8 2007-11-08 5 Fedora 9 2008-05-13 6 Fedora 10 2008-11-25 7 SUSE 10.1 2006-05-11 8 SUSE 10.2 2006-12-07 9 SUSE 10.3 2007-10-04 10 SUSE 11.0 2008-06-19 11 Ubuntu 6.06 2006-06-01 12 Ubuntu 6.10 2006-10-26 13 Ubuntu 7.04 2007-04-19 14 Ubuntu 7.10 2007-10-18 15 Ubuntu 8.04 2008-04-24 16 Ubuntu 8.10 2008-10-30 End Of Report 我们的报告是我们一系列命令的结果。首先,我们按发行版名称和版本(字段1和2)对列表进行排序,然后使用 sed 处理结果,添加报告标题(包括nl的逻辑页面标记)和页脚。最后,我们使用 nl 处理结果,默认情况下,nl 只对属于逻辑页面正文部分的文本流行进行编号。
我们可以重复该命令,并尝试不同的 nl 选项。以下是一些有趣的选项:
xxxxxxxxxxnl -n rz右对齐,有前导0。
和下面的:
xxxxxxxxxxnl -w 3 -s ' '编号占三位,编号和条目之间有一个 -s 指定的字符(本例中为空格)
fold —— 将每行包裹到指定长度
fold —— 折叠
folding 是按指定宽度分割文本行的过程。与我们的其他命令一样, fold 接受一个或多个文本文件或标准输入。如果我们发送一个简单的文本流,我们可以看到它是如何工作的。
xxxxxxxxxx[me@linuxbox ~]$ echo "The quick brown fox jumps over the lazy dog." | fold -w 12 The quick br own fox jump s over the lazy dog.在这里,我们看到了行动中的 fold 。 echo 命令发送的文本被分解为由 -w 选项指定的段。在这个例子中,我们指定了12个字符的线宽。如果未指定宽度,则默认为80个字符。请注意,无论单词边界如何,行都是断开的。添加 -s 选项将导致 fold 在达到线宽之前的最后一个可用空间处打断行(即不会截断单词):
xxxxxxxxxx[me@linuxbox ~]$ echo "The quick brown fox jumps over the lazy dog." | fold -w 12 -s The quick brown fox jumps over the lazy dog.fmt —— 一个简单的文本格式化工具
fmt 程序还可以折叠文本,以及更多内容。它接受文件或标准输入,并对文本流执行段落格式化。基本上,它填充和连接文本中的行,同时保留空白行和缩进。
为了演示,我们需要一些文本。让我们从 fmt 信息页面上读一些。
xxxxxxxxxx `fmt' reads from the specified FILE arguments (or standard input if none are given), and writes to standard output. By default, blank lines, spaces between words, and indentation arepreserved in the output; successive input lines with differentindentation are not joined; tabs are expanded on input and introduced on output. `fmt' prefers breaking lines at the end of a sentence, and tries to avoid line breaks after the first word of a sentence or before the last word of a sentence. A "sentence break" is defined as either the end of a paragraph or a word ending in any of `.?!', followed by two spaces or end of line, ignoring any intervening parentheses or quotes. Like TeX, `fmt' reads entire "paragraphs" before choosing line breaks; the algorithm is a variant of that given by Donald E. Knuth and Michael F. Plass in "Breaking Paragraphs Into Lines", `Software--Practice & Experience' 11, 11 (November 1981), 1119-1184.我们将把此文本复制到文本编辑器中,并将文件另存为 fmt-info.txt 。现在,假设我们想重新格式化此文本以适应50个字符宽的列。我们可以通过使用 fmt 和 -w 选项处理文件来实现这一点。
xxxxxxxxxx[me@linuxbox ~]$ fmt -w 50 fmt-info.txt | head 'fmt' reads from the specified FILE arguments (or standard input if none are given), and writes to standard output. By default, blank lines, spaces between words, and indentation are preserved in the output; successive input lines with different indentation are not joined; tabs are expanded on input and introduced on output.好吧,这是一个尴尬的结果。也许我们真的应该读这篇文章,因为它解释了发生了什么。
默认情况下,输出中保留空行、单词之间的空格和缩进;具有不同缩进的连续输入线不连接;选项卡在输入时展开,在输出时引入。
因此,fmt 保留了第一行的缩进。幸运的是, fmt 提供了一个纠正此问题的选项。
xxxxxxxxxx[me@linuxbox ~]$ fmt -cw 50 fmt-info.txt 'fmt' reads from the specified FILE arguments (or standard input if none are given), and writes to standard output. By default, blank lines, spaces between words, and indentation are preserved in the output; successive input lines with different indentation are not joined; tabs are expanded on input and introduced on output. 'fmt' prefers breaking lines at the end of a sentence, and tries to avoid line breaks after the first word of a sentence or before the last word of a sentence. A "sentence break" is defined as either the end of a paragraph or a word ending in any of '.?!', followed by two spaces or end of line, ignoring any intervening parentheses or quotes. Like TeX, 'fmt' reads entire "paragraphs" before choosing line breaks; the algorithm is a variant of that given by Donald E. Knuth and Michael F. Plass in "Breaking Paragraphs Into Lines", 'Software--Practice & Experience' 11, 11 (November 1981), 1119-1184.好多了。通过添加 -c 选项,我们现在得到了所需的结果。
fmt 有一些有趣的选项,如下表所示:
| 选项 | 含义 |
|---|---|
| -c | 在 crown margin 模式下操作。 这保留了段落前两行的缩进。后续行与第二行的缩进对齐。 |
| -p string | 仅格式化以前缀 string 开头的行。 格式化后,string 的内容将前缀到每一行。此选项可用于设置源代码注释中的文本格式。例如,任何使用“#”字符来描述注释的编程语言或配置文件都可以通过指定 -p '#' 来格式化,这样只有注释才会被格式化。请参阅下面的示例。 |
| -s | 仅拆分(split-only)模式。 在此模式下,行将仅被拆分以适应指定的列宽。短线不会连接以填充行。当格式化不需要连接的文本(如代码)时,此模式非常有用。 |
| -u | 执行均匀间距。 这将对文本应用传统的“打字机风格(typewriter-style)”格式。这意味着单词之间只有一个空格,句子之间有两个空格。此模式可用于删除“对齐(justification)”,即用空格填充的文本,以强制在左右边距上对齐。 |
| -w width | 设置文本格式,使其适合字符宽的列宽。 默认值为75个字符。注意: fmt 实际上会格式化比指定宽度稍短的行,以实现行平衡。 |
-p 选项特别有趣。有了它,我们可以格式化文件的选定部分,前提是要格式化的行都以相同的字符序列开头。许多编程语言使用井号(#)表示注释的开头,因此可以使用此选项进行格式化。让我们创建一个文件,模拟一个使用注释的程序。
xxxxxxxxxx[me@linuxbox ~]$ cat > fmt-code.txt# This file contains code with comments.# This line is a comment. # Followed by another comment line. # And another. This, on the other hand, is a line of code. And another line of code. And another.我们的示例文件包含以字符串“#”开头的注释(一个#后跟一个空格)和不以字符串“#”开头的代码行。现在,使用 fmt ,我们可以格式化注释并保持代码不变。
xxxxxxxxxx[me@linuxbox ~]$ fmt -w 50 -p '# ' fmt-code.txt # This file contains code with comments. # This line is a comment. Followed by another # comment line. And another. This, on the other hand, is a line of code. And another line of code. And another.请注意,相邻的注释行已连接,而空白行和不以指定前缀开头的行将保留。
pr —— 为打印格式化文本
pr 程序用于对文本进行分页(paginate)。打印文本时,通常希望用几行空白分隔输出页面,为每页提供上边距和下边距。此外,这些空白可用于在每页上插入页眉和页脚。
我们将通过将我们的 distros.txt 文件格式化为一系列短页面(仅显示前两页)来演示 pr :
xxxxxxxxxx[me@linuxbox ~]$ pr -l 15 -w 65 distros.txt2025-12-11 18:27 distros.txt P age 1 SUSE 10.2 12/07/2006 Fedora 10 11/25/2008 SUSE 11.0 06/19/2008 Ubuntu 8.04 04/24/2008 Fedora 8 11/08/20072025-12-11 18:27 distros.txt Page 2 SUSE 10.3 10/04/2007 Ubuntu 6.10 10/26/2006 Fedora 7 05/31/2007 Ubuntu 7.10 10/18/2007 Ubuntu 7.04 04/19/2007在这个例子中,我们使用 -l 选项(用于页面长度,length)和 -w 选项(页面宽度,width)来定义一个65列宽、15行长的“页面”。 pr 对 distors.txt 文件的内容进行分页,用几行空格分隔每个页面,并创建一个包含文件修改时间、文件名和页码的默认标头。 pr 程序提供了许多选项来控制页面布局。我们将在【第22章.打印】中了解它们
printf —— 格式化和打印数据
与本章中的其他命令不同, printf 命令不用于管道(它不接受标准输入),也不直接在命令行上找到频繁的应用程序(它主要用于脚本)。那么,为什么它很重要呢?因为它被广泛使用。
printf (来自短语“print formated”)最初是为C编程语言开发的,并已在包括shell在内的许多编程语言中实现。事实上,在bash中,printf 是一个内置函数。
printf 的工作原理如下:
printf [-v var] "format" arguments
命令会收到一个包含格式描述的字符串,然后将其应用于参数列表。除非指定了 -v 选项,否则格式化结果将被发送到标准输出。在这种情况下,格式化结果将存储在变量 var 中。以下是 printf 的一个简单示例:
xxxxxxxxxx[me@linuxbox ~]$ printf "I formatted the string: %s\n" foo I formatted the string: foo在这里,它再次使用 -v 选项,将结果放置在变量中,而不是发送到标准输出:
xxxxxxxxxx[me@linuxbox ~]$ printf -v result "I formatted the string: %s\n" foo [me@linuxbox ~]$ echo "$result"I formatted the string: foo格式字符串可能包含文字文本(如 "I formatted the string:")、转义序列(如 \n 换行符)和以 % 字符开头的序列,这些被称为转换规范,conversion specifications 。在上面的示例中,转换规范 %s 用于格式化字符串“foo”并将其放置在命令的输出中。再来一个例子:
xxxxxxxxxx[me@linuxbox ~]$ printf "I formatted '%s' as a string.\n" foo I formatted 'foo' as a string.正如我们所看到的, %s 转换规范在命令输出中被字符串“foo”替换。s 转换用于格式化字符串数据。其他类型的数据还有其他说明符。下表列出了常用的数据类型。
| 指定者 | 描述 |
|---|---|
| d | 将数字格式化为带符号的十进制整数。 |
| f | 格式化并输出浮点数。 |
| o | 将整数格式化为八进制数。 |
| s | 格式化字符串。 |
| x | 在需要时使用小写 a 到 f 将整数格式化为十六进制数。 |
| X | 与x相同,但使用大写字母。 |
| % | 打印文字%符号(即指定%%) |
我们将演示每个转换说明符对字符串380的影响。
xxxxxxxxxx[me@linuxbox ~]$ printf "%d, %f, %o, %s, %x, %X\n" 380 380 380 380 380 380 380, 380.000000, 574, 380, 17c, 17C由于我们指定了六个转换说明符,我们还必须为 printf 提供六个参数以进行处理。这六个结果显示了每个说明符的效果。
转换说明符中可以添加几个可选组件来调整其输出。完整的转换规范可能包括以下内容:
%[flags][width][.precision]conversion_specification
使用多个可选组件时,必须按照前面指定的顺序出现,才能正确解释。下表描述了每种情况。
| 组成部分 | 描述 |
|---|---|
| flags | 有五种不同的标记: |
# :使用“替代格式”进行输出。这因数据类型而异。对于o(八进制数)转换,输出前缀为0。对于x和x(十六进制数)转换,输出分别以0x或0x作为前缀。 | |
0 :用零填充输出。这意味着该字段将填充前导零,如000380中所示。 | |
- :左对齐输出。默认情况下,printf对输出进行右对齐。 | |
| |
+ :签署正数。默认情况下, printf 只对负数签名。 | |
| width | 指定最小字段宽度的数字。 |
| .precision | 对于浮点数,指定小数点后要输出的精度位数。 对于字符串转换, precision 指定要输出的字符数(会截断后面的字符)。 |
下表列出了不同格式的一些示例:
| 参数 | 格式 | 结果 | 备注 |
|---|---|---|---|
| 380 | "%d" | 380 | 整数的简单格式化 |
| 380 | "%#x" | 0x17c | 使用“备用格式(alternate format)”标志格式化为十六进制数的整数。 |
| 380 | "%05d" | 00380 | 带前导零(padding,填充)的整数格式,最小字段宽度为五个字符。 |
| 380 | "%05.5f" | 380.00000 | 格式化为带填充和五位小数精度的浮点数的数字。由于指定的最小字段宽度(5)小于格式化数字的实际宽度,因此填充无效。 |
| 380 | "%010.5f" | 0380.00000 | 通过将最小字段宽度增加到10,填充现在可见。 |
| 380 | "%+d" | +380 | +标志表示正数。 |
| 380 | "%-d" | 380 | 左侧的 - 标志用于对齐格式。 |
| abcdefghijk | "%5s" | abcdefghijk | 用最小字段宽度格式化的字符串。 |
| abcdefghijk | "%.5s" | abcde | 通过对字符串应用精度,它会被截断。 |
同样,printf 主要用于脚本中,用于格式化表格数据,而不是直接在命令行上使用。但我们仍然可以展示如何使用它来解决各种格式问题。首先,让我们输出一些用制表符(\t)分隔的字段。
xxxxxxxxxx[me@linuxbox ~]$ printf "%s\t%s\t%s\n" str1 str2 str3 str1 str2 str3通过插入 \t (选项卡的转义序列),我们实现了预期的效果。接下来,这里有一些格式整洁的数字:
xxxxxxxxxx[me@linuxbox ~]$ printf "Line: %05d %15.3f Result: %+15d\n" 1071 3.14156295 32589 Line: 01071 3.142 Result: +32589这显示了最小场宽度对场间距的影响。或者格式化一个小网页怎么样?
xxxxxxxxxx[me@linuxbox ~]$ printf "<html>\n\t<head>\n\t\t<title>%s</title>\n\t</head>\n\t<body>\n\t\t<p>%s</p>\n\t</body>\n</html>\n" "Page Title" "Page Content" <html> <head> <title>Page Title</title> </head> <body> <p>Page Content</p> </body> </html>文档格式系统
到目前为止,我们已经研究了简单的文本格式化工具。这些适用于小型、简单的任务,但大型工作呢?Unix成为技术和科学用户中流行的操作系统的原因之一(除了为各种软件开发提供强大的多任务、多用户环境外)是它提供了可用于生成多种类型文档的工具,特别是科学和学术出版物。事实上,正如GNU文档所描述的那样,文档准备(document preparation)对Unix的发展起到了重要作用。
The first version of UNIX was developed on a PDP-7 which was sitting around Bell Labs. In 1971 the developers wanted to get a PDP-11 for further work on the operating system. In order to justify the cost for this system, they proposed that they would implement a document formatting system for the AT&T patents division. This first formatting program was a reimplementation of McIllroy's `roff', written by J. F. Ossanna.
UNIX的第一个版本是在贝尔实验室附近的PDP-7上开发的。1971年,开发人员希望获得PDP-11,以进一步开发操作系统。为了证明该系统的成本是合理的,他们建议为AT&T专利部门实施一个文档格式系统。这个第一个格式化程序是由J.F.Ossanna编写的McIlroy的“roff”的重新实现。
两个主要的文档格式化程序家族主导着该领域:一个是源自原始(original) roff 程序的,包括 nroff 和 troff ,另一个是基于Donald Knuth的TEX(发音为“tek”)排版系统的。是的,中间掉下来的“E”是它名字的一部分。
“roff”这个名字来源于“run off”(复印,影印)一词,如“我会为你打印一份副本”。 nroff 程序用于格式化文档,以便输出到使用等宽字体的设备,如字符终端和打字机式(typewriter-style)打印机。在推出时,这包括几乎所有连接到计算机的打印设备。后来的 troff 程序格式化文档,以便在排字机(typesetters)上输出,排字机是用于为商业印刷生产“相机就绪”(camera-ready)字体的设备。如今,大多数计算机打印机都能够模拟排字机的输出。 roff 家族还包括一些用于准备部分文档的其他程序。其中包括 eqn (用于数学方程)和 tbl (用于表格)。
TEX系统(稳定形式)于1989年首次出现,在某种程度上取代了 troff ,成为排版输出的首选工具。我们不会在这里介绍TEX,这既是因为它的复杂性(有很多关于它的书),也是因为它在大多数现代Linux系统上都没有默认安装。
提示:对于那些有兴趣安装TEX的人来说,可以查看大多数发行库中的texlive包和LyX图形内容编辑器。
groff
groff 是一套包含 troff 的GNU实现的程序。它还包括一个用于模拟 nroff 和 roff 家族其他成员的脚本。
虽然 roff 及其后代用于制作格式化文档,但它们的方式对现代用户来说相当陌生。如今,大多数文档都是使用文字处理器生成的,这些文字处理器能够在一个步骤中完成文档的组成和布局。在图形文字处理器出现之前,文档通常是通过两步过程生成的,包括使用文本编辑器进行排版,以及使用 troff 等处理器进行格式化。格式化程序的指令通过使用标记(markup)语言嵌入到编写的文本中。这种过程的现代类比是网页,它使用某种文本编辑器编写,然后由网络浏览器使用HTML作为标记语言呈现,以描述最终的页面布局。
我们不会全面介绍 groff ,因为它的标记语言的许多元素都涉及排版中相当晦涩的细节。相反,我们将专注于它仍然广泛使用的宏包(macro packages)之一。这些宏包将许多低级命令压缩为一组较小的高级命令,使 groff 的使用更加容易。
让我们考虑一下谦逊的(humble)手册页。它以 gzip 压缩文本文件的形式存在于 /usr/share/man 目录中。如果我们检查其未压缩的内容,我们会看到以下内容(显示了 ls 的手册页的第一节):
xxxxxxxxxx[me@linuxbox ~]$ zcat /usr/share/man/man1/ls.1.gz | head .\" DO NOT MODIFY THIS FILE! It was generated by help2man 1.47.3..TH LS "1" "January 2025" "GNU coreutils 8.28" "User Commands".SH NAMEls \- list directory contents.SH SYNOPSIS.B ls[\fI\,OPTION\/\fR]... [\fI\,FILE\/\fR]....SH DESCRIPTION.\" Add any additional description here.PP与正常显示的手册页相比,我们可以开始看到标记语言与其结果之间的相关性。
xxxxxxxxxx[me@linuxbox ~]$ man ls | head LS(1) User Commands LS(1) NAME ls - list directory contents SYNOPSIS ls [OPTION]... [FILE]...令人感兴趣的原因是,手册页是由 groff 使用 mandoc 宏包呈现的。事实上,我们可以用以下管道模拟 man 命令:
xxxxxxxxxx[me@linuxbox ~]$ zcat /usr/share/man/man1/ls.1.gz | groff -mandoc -T ascii | head LS(1) User Commands LS(1) NAME ls - list directory contents SYNOPSIS ls [OPTION]... [FILE]...在这里,我们使用带有选项集的 groff 程序来指定 mandoc 宏包和ASCII的输出驱动程序。 groff 可以生成多种格式的输出。如果未指定格式,则默认输出PostScript。
xxxxxxxxxx[me@linuxbox ~]$ zcat /usr/share/man/man1/ls.1.gz | groff -mandoc | head %!PS-Adobe-3.0 %%Creator: groff version 1.18.1 %%CreationDate: Thu Feb 5 13:44:37 2025 %%DocumentNeededResources: font Times-Roman %%+ font Times-Bold %%+ font Times-Italic %%DocumentSuppliedResources: procset grops 1.18 1 %%Pages: 4 %%PageOrder: Ascend %%Orientation: Portrait我们在上一章中简要提到了PostScript,并将在下一章中再次提到。PostScript是一种页面描述语言(page description language),用于向类似排字机的设备描述打印页面的内容。如果我们获取命令的输出并将其存储到文件中(假设我们使用的是具有desktop目录的图形桌面),则输出文件的图标应出现在桌面上。
xxxxxxxxxx[me@linuxbox ~]$ zcat /usr/share/man/man1/ls.1.gz | groff -mandoc > ~/Desktop/ls.ps通过双击图标,页面查看器应启动并显示文件的呈现形式,如下图所示:
我们看到的是一个排版精美的ls手册页!事实上,可以使用以下命令将PostScript文件转换为可移植文档格式(Portable Document Format,PDF)文件:
xxxxxxxxxx[me@linuxbox ~]$ ps2pdf ~/Desktop/foo.ps ~/Desktop/ls.pdfps2pdf 程序是 ghostscript 包的一部分,该包安装在大多数支持打印的Linux系统上。
提示:Linux系统通常包含许多用于文件格式转换的命令行程序。它们通常使用format2format 的约定命名。尝试使用命令 ls /usr/bin/*[[:alpha:]]2[[:alpha:]]* 来识别它们。还可以尝试搜索名为 formattoformat 的程序。
在我们与 groff 的最后一个练习中,我们将重新审视我们的老朋友 distros.txt 。这一次,我们将使用 tbl 程序,该程序用于格式化表以排版我们的Linux发行版列表。为此,我们将使用之前的 sed 脚本向文本流中添加标记,并将其提供给 groff 。
首先,我们需要修改 sed 脚本,以添加 tbl 所需的必要标记元素(在 groff 中称为请求,requests)。使用文本编辑器,我们将把 distros.sed 更改为以下内容:
xxxxxxxxxx# sed script to produce Linux distributions report 1 i\ .TS\ center box;\ cb s s\ cb cb cb\ l n c.\ Linux Distributions Report\ =\ Name Version Released\ _ s/\([0-9]\{2\}\)\/\([0-9]\{2\}\)\/\([0-9]\{4\}\)$/\3-\1-\2/ $ a\ .TE请注意,为了使脚本正常工作,必须注意用制表符而不是空格分隔单词【Name Version Released】。我们将把生成的文件另存为 distros-tbl.sed 。tbl使用 .TS 和 TE 请求开始和结束表格。后面的行.TS 请求定义了表的全局属性,在我们的示例中,这些属性在页面上水平居中,并被一个框包围。定义的其余行描述了每个表行的布局。现在,如果我们使用新的sed脚本再次运行报告生成管道,我们将得到以下结果:
xxxxxxxxxx[me@linuxbox ~]$ sort -k 1,1 -k 2n distros.txt | sed -f distros-tbl.sed | groff -t -T ascii +------------------------------+ | Linux Distributions Report | +------------------------------+ | Name Version Released | +------------------------------+ |Fedora 5 2006-03-20 | |Fedora 6 2006-10-24 | |Fedora 7 2007-05-31 | |Fedora 8 2007-11-08 | |Fedora 9 2008-05-13 | |Fedora 10 2008-11-25 | |SUSE 10.1 2006-05-11 | |SUSE 10.2 2006-12-07 | |SUSE 10.3 2007-10-04 | |SUSE 11.0 2008-06-19 | |Ubuntu 6.06 2006-06-01 | |Ubuntu 6.10 2006-10-26 | |Ubuntu 7.04 2007-04-19 | |Ubuntu 7.10 2007-10-18 | |Ubuntu 8.04 2008-04-24 | |Ubuntu 8.10 2008-10-30 | +------------------------------+在 groff 中添加 -t 选项指示它使用 tbl 处理文本流。同样, -T 选项用于输出到ASCII,而不是默认的输出介质PostScript。
如果我们受限于终端屏幕或打字机式打印机的功能,输出的格式是我们所能期望的最佳格式。如果我们指定PostScript输出并以图形方式查看输出,我们会得到更令人满意的结果,如下图所示。
xxxxxxxxxx[me@linuxbox ~]$ sort -k 1,1 -k 2n distros.txt | sed -f distros-tbl.sed | groff -t > ~/Desktop/foo.ps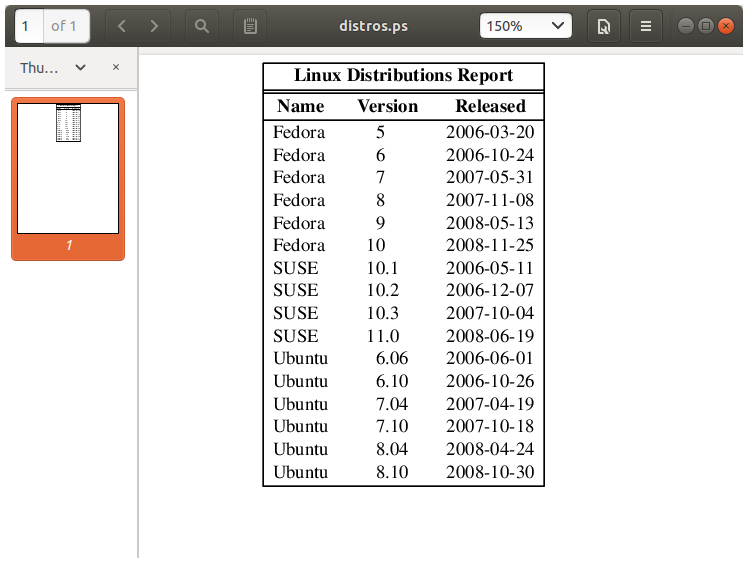
总结
鉴于文本对类Unix操作系统的特性至关重要,有许多工具用于操纵和格式化文本是有道理的。正如我们所看到的,有!像 fmt 和 pr 这样的简单格式化工具在生成短文档的脚本中有很多用途,而 groff (和朋友)可以用来写书。我们可能永远不会使用命令行工具写技术论文(尽管有很多人这样做!),但很高兴知道我们可以。